责任、验证与人的主体性
图解导读:采纳AI输出,就是接过责任
AI可以生成建议、草稿、摘要和方案,但它不能替你承担现实后果。只要你把AI输出放进作业、论文、决策或公开发布内容里,责任就已经从模型转移到了你身上。
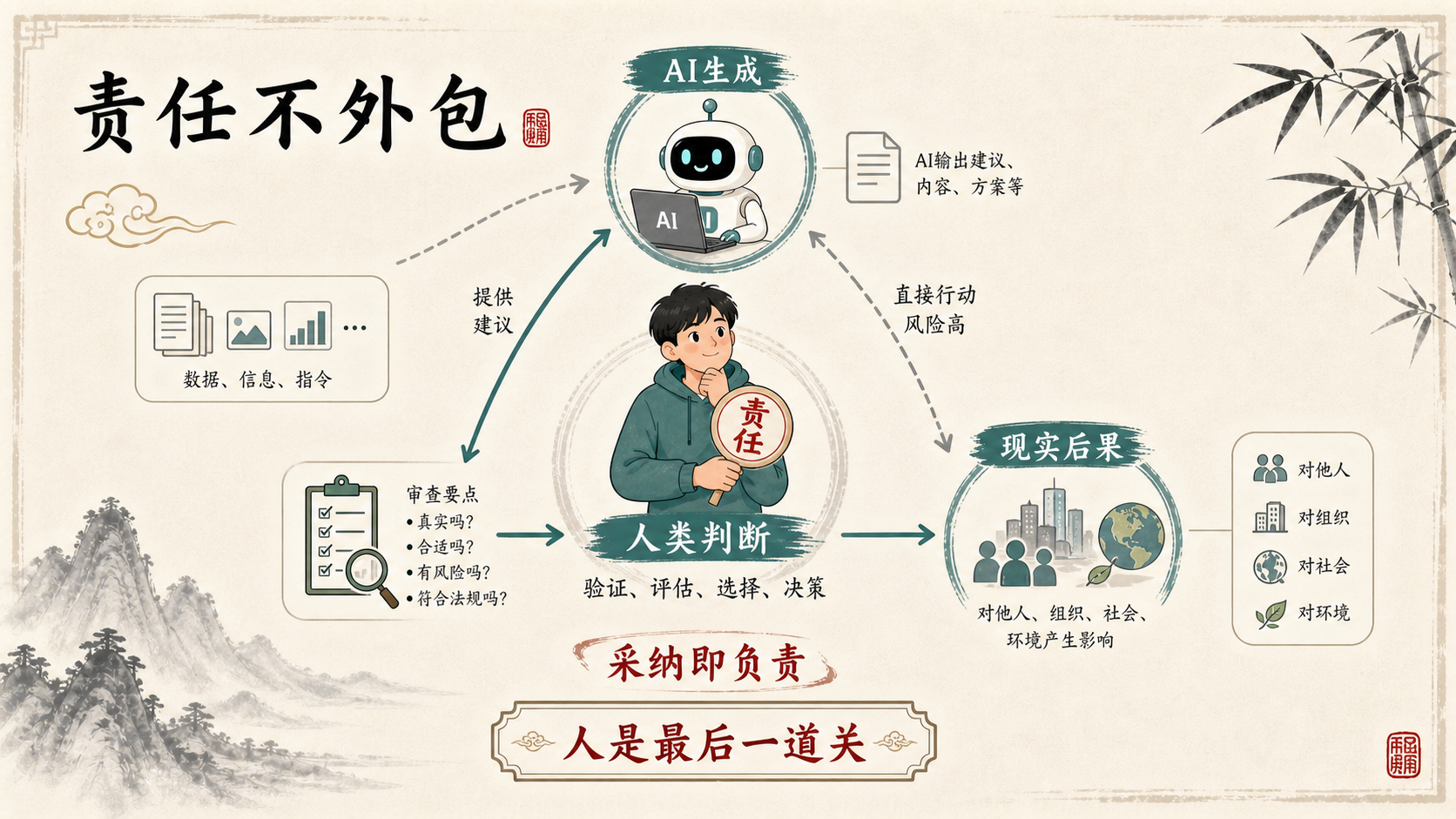
最后一章的核心动作,是把验证分层:先看格式,再核事实,再复盘逻辑,再评估风险,最后由人确认。这个过程不浪漫,却是AI时代最可靠的主体性训练。
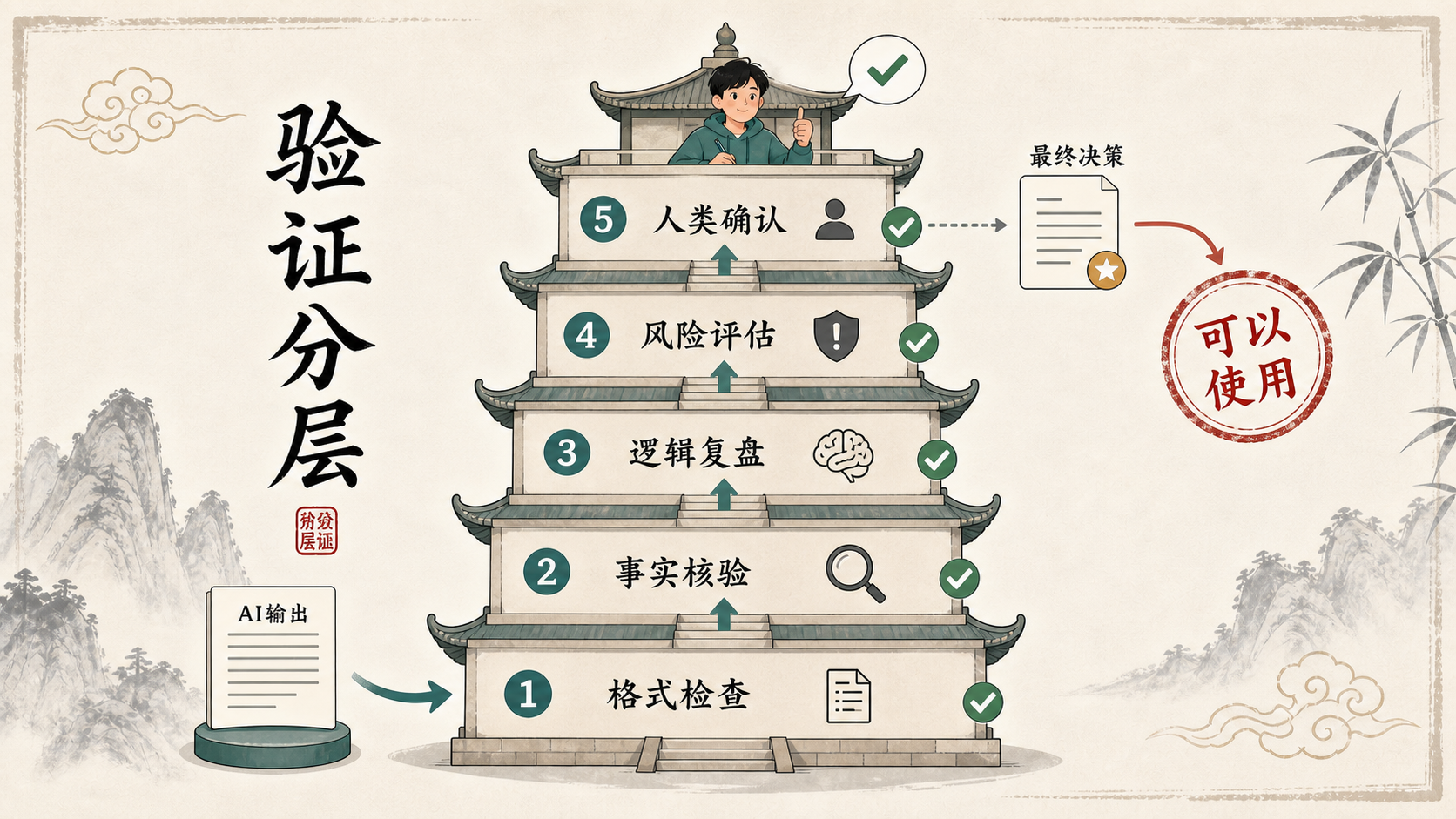
AI输出不是结论,而是待验证材料
待验证材料原则
AI的任何输出,在未经独立验证之前,都应被视为"待验证材料",而非"可信结论"。验证的严格程度应与内容的用途和影响范围成正比。
随着使用AI的时间增长,你对它的警惕性会逐渐降低。国家网信办关于《生成式人工智能服务管理暂行办法》的答记者问提醒,生成式人工智能发展带来机遇的同时,也产生传播虚假信息、侵害个人信息权益、数据安全和偏见歧视等问题[1]。
这种心理变化是自然的,但也最危险。因为AI无论多么不确定,它的语气都一样自信。你在第2章学到的"流畅性效应",会随着时间推移变得更加隐蔽 -- 你不再是被一次性的流畅所骗,而是在长期的可靠表现中逐渐放松了警惕。
区分事实、观点、推测和建议
| 类型 | 特征 | 验证方式 |
|---|---|---|
| 事实 | 可独立验证为真或假 | 核实独立来源(统计局、学术论文、官方文件) |
| 观点 | 基于价值判断的评价 | 考察论据和对立立场 |
| 推测 | 信息不完整时的预判 | 评估前提假设是否合理 |
| 建议 | 行动指导 | 判断是否适合你的场景 |
AI不会主动标注"以下是我的观点"。把所有内容混合在一起用同样的语气输出,区分是你的责任。
这四种类型在同一段AI回答中经常混合出现。例如:AI告诉你"2024年中国GDP增速为5.0%(事实)。这表明中国经济韧性强(观点)。预计2025年增速将保持在4.5%-5%之间(推测)。你的论文可以从供给侧改革的角度来分析(建议)。" 你需要对每一部分使用不同的验证方式。
来源、证据、不确定性:三层验证
索要来源:具体出处是什么?如果不确定,请直接说明。
索要证据:支撑结论的证据是什么类型?有没有反面证据?
索要不确定性:哪些部分你很有把握,哪些不确定?最可能出错的是哪里?
三层验证的实际操作
你可以在每次重要的AI交互后,追加一个标准化的验证请求:
"请对你刚才的回答做一个自检:(1) 哪些是你确信准确的事实?(2) 哪些是你的推测或判断?(3) 哪些地方你最可能出错?(4) 你引用的来源是否都真实存在?"
AI不一定能准确回答这些问题,但这个过程会迫使它重新审视自己的输出,有时能暴露出隐藏的不确定性。
伪引用识别
AI生成伪引用的方式:根据训练数据的模式,拼接出一个"看起来像真的"论文引用 -- 真实的作者名 + 真实的期刊名 + 合理的年份 + 从未发表过的标题。
识别方法:
- 到Google Scholar / CNKI(中国知网) / Web of Science搜索完整标题
- 核对作者、年份、期刊是否匹配
- 检查DOI是否有效
- 标题"过于完美地回答了你的问题" -- 高度可疑。如果一篇论文的标题看起来就是为你的问题量身定做的,它很可能是AI编造的
科技部监督司发布的《负责任研究行为规范指引(2023)》明确要求,使用生成式人工智能生成的内容,特别是涉及事实和观点等关键内容的,应明确标注并说明其生成过程,确保真实准确和尊重他人知识产权[2]。这进一步说明了独立核实引用的重要性 -- 不能因为AI"看起来很确定"就放弃验证。
实操练习:识别以下引用是真是假
假设 AI 在你的论文中生成了这条引用:
张明远, 李志华. (2024). 生成式人工智能对大学生批判性思维的影响机制研究.《高等教育研究》, 45(3), 67-78.
核实步骤:
- 到中国知网(CNKI)搜索完整标题 -- 查不到?高度可疑
- 搜索作者名 + 期刊名 -- 确认该作者是否在该期刊发表过文章
- 检查卷号和页码 -- 《高等教育研究》第45卷3期是否存在,页码67-78是否匹配
- 标题"太完美地回答了你的问题" -- 这本身就是一个警告信号
如果步骤一就查不到,这条引用几乎确定是AI编造的。
学术诚信
学术诚信的光谱:
| 位置 | 行为 | 性质 |
|---|---|---|
| 合理辅助 | 语法检查、概念理解、翻译润色、框架整理 | 可接受 |
| 灰色地带 | AI生成大纲你填内容、AI重写段落 | 需披露 |
| 代写 | AI生成完整作品直接提交 | 学术不端 |
| 伪造 | AI编造数据、虚构引用 | 严重不端 |
判断是否越界的三个自问:
- 学习目的检验:我的使用方式是否绕过了学习目的?
- 智力贡献检验:去掉AI内容后还能体现我的思考吗?
- 可解释性检验:老师追问任何细节我都能解释吗?
在灰色地带中,披露是最安全的选择。
《负责任研究行为规范指引(2023)》已经对生成式人工智能内容标注提出明确要求[2:1]。越来越多的高校也在制定自己的AI使用规范。坦诚标注你使用了AI,不会降低你的工作价值 -- 关键在于你是否在AI的基础上进行了自己的思考、验证和改进。
隐私与数据安全
不应发给云端AI的内容:
- 他人的隐私信息(姓名、身份证号、联系方式)
- 商业机密和保密信息
- 未发表的核心学术成果
- 密码和API Key
- 涉及国家安全的信息
处理敏感数据时
先做脱敏处理(去除可识别个人身份的信息),再交给AI处理。或使用本地部署的模型。
《中华人民共和国个人信息保护法》和《生成式人工智能服务管理暂行办法》对个人信息处理和生成式人工智能服务都有明确规定[3][4]。作为使用者,你有责任确保不将他人的个人信息未经授权地提供给AI服务。
沙箱、日志、Checkpoints与Diff
| 机制 | 作用 |
|---|---|
| 沙箱 | 隔离AI的执行环境,限制影响范围 |
| 日志 | 记录AI的每一步操作,供事后审查 |
| Checkpoints | 操作前保存快照,出错可恢复 |
| Diff | 直观展示AI修改了什么,让你一目了然地看到变化 |
可回退性是这张安全网的核心。操作越不可逆,执行前的审查就应该越严格。删除一个文件比创建一个文件需要更多的审查;发送一封邮件比起草一封邮件需要更多的确认。
人工确认的必要性
人工确认不是效率的敌人,而是主体性的保障。
三种确认粒度:
- 逐步确认:最安全,效率最低,适合不熟悉的工具或高风险操作
- 批次确认:安全与效率的平衡,适合日常工作
- 结果确认:效率最高,风险最大,仅适合全部可回退的场景
选择哪种粒度取决于两个因素:你对工具的熟悉程度和操作的可回退性。新手用新工具应该逐步确认;老手做可回退的操作可以结果确认。
成为AI时代的主动学习者
回顾全书15章,你已经建立起一套完整的AI素养框架:
| 能力层 | 核心章节 | 你学到了什么 |
|---|---|---|
| 认知基础 | Ch1-2 | AI是生成器而非数据库,清醒使用者的四大支柱 |
| 提问能力 | Ch3-5 | BACS框架、任务拆解、上下文工程、迭代式协作 |
| 学习能力 | Ch6-7 | 费曼检验、苏格拉底追问、思维陡练、事前验尸 |
| 判断能力 | Ch8-9 | 品味与审美、七问法质量评估框架 |
| 工具素养 | Ch10-14 | 文件格式、结构化表达、AI产品形态、工具连接、技术环境 |
| 责任意识 | Ch15 | 验证分层、学术诚信、隐私保护、人的主体性 |
被动使用者:模糊要求 -> 接受第一个回答 -> 不验证 -> AI变强了,人变弱了。
主动驾驭者:精准要求 -> 迭代协作 -> 验证判断 -> AI变强了,人也变强了。
AI时代人的不可替代能力:
- 问题定义 -- 在混沌中识别真正的问题
- 专业判断 -- 在AI的选项中做出最优选择
- 责任承担 -- 对决策后果负责
- 关系建设 -- 在人与人之间建立信任
- 创造性整合 -- 跨领域知识的融合创新
AI可以帮你走得更快,但你自己决定走向哪里。AI可以帮你看得更远,但你自己决定看见什么。
本章核心回顾
- AI输出是待验证材料,不是可信结论
- 区分事实、观点、推测和建议,追问来源、证据和不确定性
- 学术诚信的关键:学习目的、智力贡献、可解释性三个自问
- 隐私数据先脱敏再交给AI,遵守个人信息保护法
- 沙箱、日志、Checkpoints、Diff构成安全防护网
- 人工确认维护的是人的主体性
- 做主动驾驭者,不做被动消费者
在AI时代,'人的主体性'最核心的含义是什么?
AI生成的引用'过于完美地回答了你的问题'时,你应该怎么做?
如果你的毕业论文中有30%的内容是在AI辅助下完成的,你认为应该如何向导师和读者说明?
回顾你在这本书中学到的所有内容,试着用一句话概括:在AI时代,你作为一个大学生,最核心的能力是什么?
参考文献
国家互联网信息办公室. (2023). 国家互联网信息办公室有关负责人就《生成式人工智能服务管理暂行办法》答记者问. https://www.cac.gov.cn/2023-07/13/c_1690898326863363.htm ↩︎
科技部监督司. (2023).《负责任研究行为规范指引(2023)》. https://www.most.gov.cn/kjbgz/202312/t20231221_189240.html ↩︎ ↩︎
全国人大常委会. (2021).《中华人民共和国个人信息保护法》. https://www.npc.gov.cn/npc/c2/c30834/202108/t20210820_313088.html ↩︎
国家互联网信息办公室等七部门. (2023).《生成式人工智能服务管理暂行办法》. https://www.cac.gov.cn/2023-07/13/c_1690898327029107.htm ↩︎