Context:会用AI的人,会准备工作环境
图解导读:上下文就是AI的工作台
Context听起来像技术词,其实可以理解成你给AI布置的工作台。背景、目标、材料、约束、示例和输出格式越清楚,AI越像是在一张干净桌面上工作;如果这些信息混在一起,它就只能在一堆纸里猜你的意思。
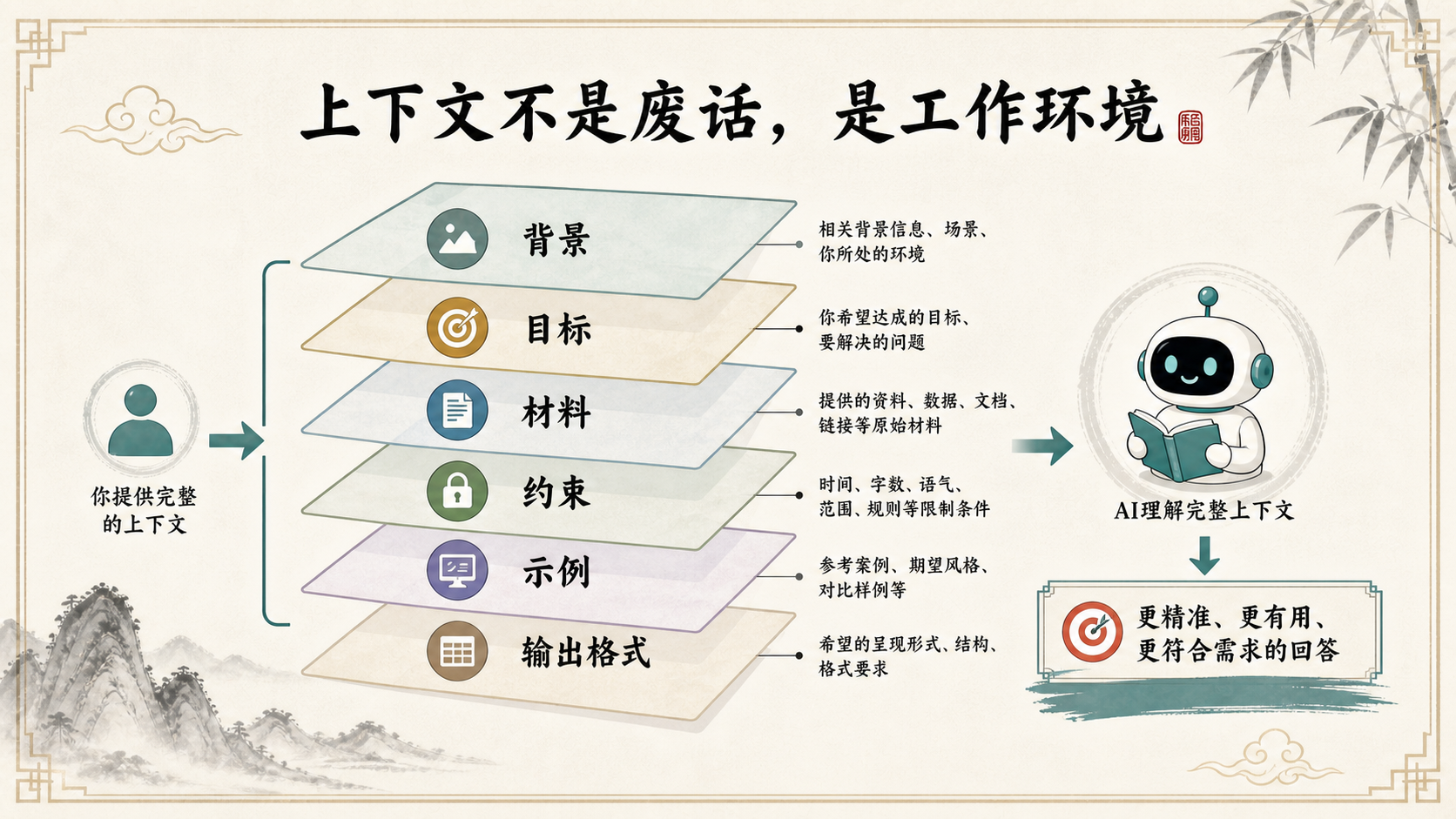
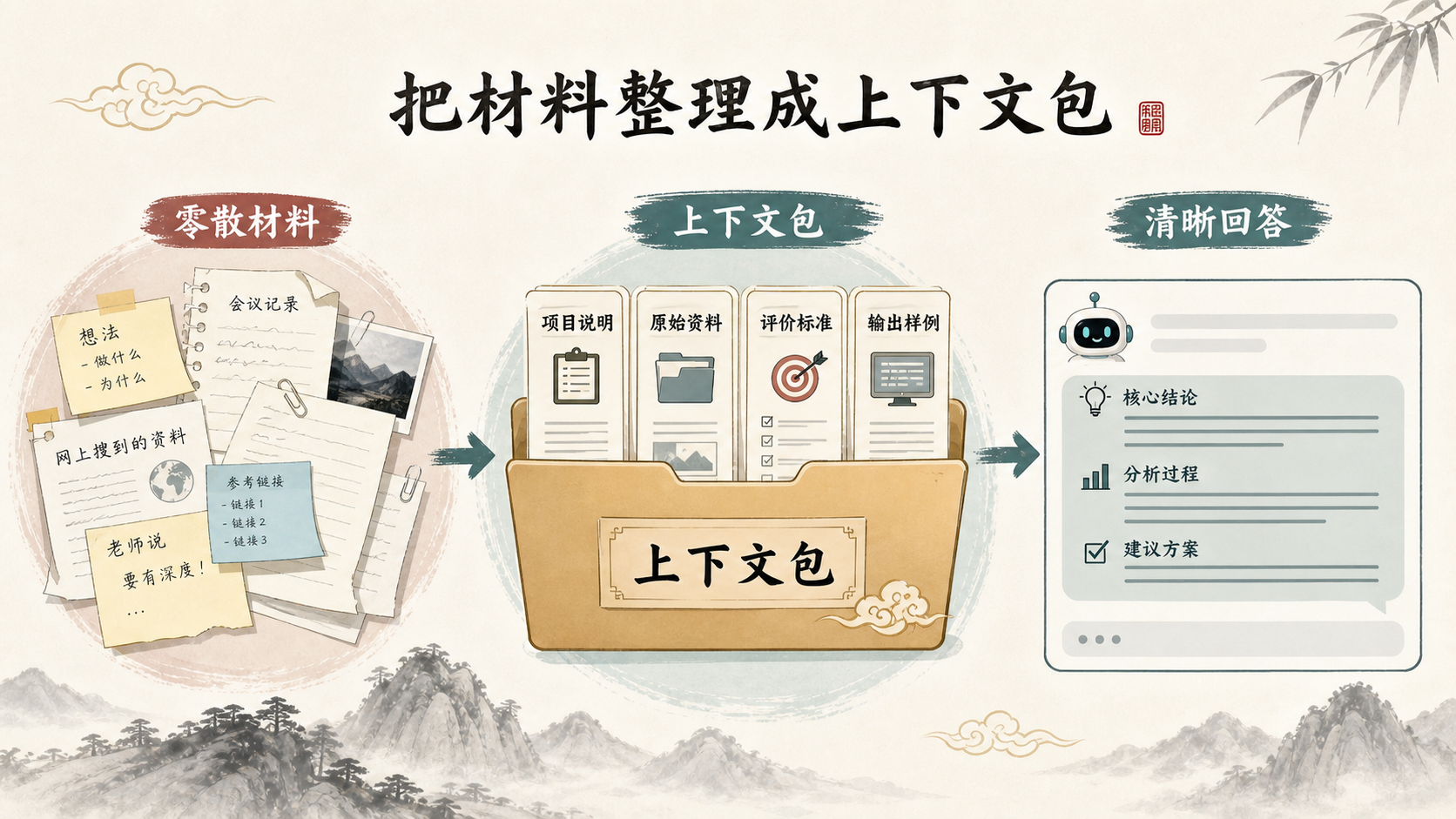
一个好习惯是把材料打成"上下文包":项目说明告诉它为什么做,原始资料告诉它依据在哪里,评价标准告诉它什么算好,输出样例告诉它最后长什么样。这样,AI不是凭空发挥,而是在你的材料边界内工作。
什么是上下文
定义:上下文(Context)
在AI交互中,上下文是指模型在生成回答时能够参考的全部信息。它包括当前对话的历史消息、用户上传的文件和数据、系统预设的指令、以及通过工具调用获取的外部信息。上下文的质量和组织方式,直接决定了AI输出的质量。
你可以把AI想象成一位能力很强但对你的项目一无所知的新员工。如果你只说"帮我写一份竞品分析报告",他只能按教科书写。但如果你花半小时做"入职培训",提供产品手册、市场月报和老板重点方向,写出来的报告质量完全不同。那半小时的入职培训,就是你在为AI准备上下文。
随着RAG、文件对话和知识库问答等应用普及,"上下文"已经不只是聊天记录,而是模型可参考的任务材料、外部文档和检索结果。通信学报关于本地知识库应用的文章把RAG流程拆解为加载文档、切分、向量化、检索、构造提示词和生成回答等环节[1]。这说明:与其纠结于措辞技巧,不如把精力放在给AI准备更好的工作材料上。
上下文的四个层次
| 层次 | 来源 | 说明 |
|---|---|---|
| 对话上下文 | 当前对话历史 | 你和AI说过的一切,累积影响后续回答 |
| 文件上下文 | 上传的文档 | 你主动提供的PDF、数据、参考材料 |
| 项目上下文 | 跨会话记忆 | AI记住的你的偏好、项目背景等长期信息 |
| 工具上下文 | AI主动获取 | AI通过搜索、代码执行等工具获得的信息 |
理解这四个层次很重要,因为它们的可控性不同。对话上下文和文件上下文完全由你掌控,你可以精心组织它们。项目上下文部分由你控制(你可以设置偏好),部分由系统管理。工具上下文则基本由AI自主决定 -- 你可以引导它去搜索,但不能精确控制它搜到什么。
同一问题在不同上下文下答案不同
直接问"人工智能对社会有什么影响?",你会得到一篇百科式概述。
但如果AI知道你是新闻传播学大三学生,正在写深度伪造对新闻可信度影响的论文,它的回答会聚焦在AI生成内容对信息生态的冲击、深度伪造对公众信任的侵蚀等具体问题上。
上下文改变输出的三个机制
1. 方向聚焦 - 缩小可能性空间,深入特定方向。当AI知道你在写深度伪造的论文,它不会浪费篇幅去讲自动驾驶和医疗AI。
2. 语言风格校准 - 自动匹配你使用的语体。如果你的上下文是学术论文的一部分,AI会自动采用学术写作的语言风格;如果是给客户的邮件,它会切换到商务语言。
3. 知识激活 - "唤醒"与当前话题相关的知识网络。上下文就像搜索引擎中的关键词组合,越精确的组合,激活的知识越相关。
RAG技术的核心价值正在于让模型先检索外部资料,再基于检索到的内容生成回答。相关研究指出,这种方式能够缓解知识过时、语料不足和答案不可靠等问题[1:1][2]。这个机制有一个直觉上容易理解的解释:当AI有足够的真实材料可以"参考"时,它就不需要去"编造"了。
上下文质量自检
在向AI提交重要请求前,检查四个问题:
- 够不够? 你提供了AI理解需求所必需的背景信息吗?
- 准不准? 信息是否准确、一致?有没有矛盾的指令?
- 相关吗? 材料是否都与当前任务直接相关?
- 有结构吗? 信息是有组织地呈现,还是一团散乱的文字?
注意
好的上下文不是"多",而是"对"。精心筛选过的、与任务直接相关的、结构清晰的上下文,比一股脑倾倒的海量原始材料有效得多。就像你给新同事做入职培训,不是把公司所有文件都甩给他,而是挑出他工作中最需要的那几份。
Token与上下文窗口
Token是AI处理文本的最小单位。它不完全等同于"字"或"词"。经验估算:1000个英文Token约等于500-600个汉字。
| 模型 | 上下文窗口 | 大致相当于 |
|---|---|---|
| Claude | 约100万Token | 10-15本学术专著 |
| Gemini | 100-200万Token | 一整套课程教材 |
| GPT系列 | 约100万Token | 10-15本学术专著 |
| DeepSeek | 约100万Token | 10-15本学术专著 |
| Kimi | 约20万Token | 约2-3本学术专著 |
| 通义千问 | 约100万Token | 10-15本学术专著 |
重要提示
广告宣传的窗口大小和模型实际能高效利用的大小是两回事。研究发现,模型对文本开头和结尾的关注度明显高于中间部分 -- 这被称为**"中间丢失"(Lost in the Middle)现象**。中文信息检索领域的综述也提醒我们,大模型时代的信息组织、检索与排序依然会显著影响最终回答质量[2:1]。这意味着:较短的精炼材料往往比填满窗口的海量信息效果更好,关键材料应当放在开头或结尾等显眼位置,并用标题、列表和标签明确标注。
应对长对话失焦
经验上,一轮对话在15-30分钟、10-20轮交互以内时表现最稳定。超过这个范围,AI的表现会开始退化 -- 不是因为它"忘了",而是因为上下文中累积了太多信息,关键信息被稀释了。
四个应对策略:
- 主题切换时开新对话 - 旧话题只会占据宝贵的上下文空间。讨论完文献综述,开一个新对话来处理研究方法
- 阶段性总结 - 让AI对讨论做结构化总结,作为"记忆刷新"。然后在新对话中粘贴这份总结作为起点
- 关键信息前置 - 在新消息中主动重复关键约束。不要以为AI会"记住"十轮之前你说的要求
- 控制对话长度 - 把大任务拆成独立的短对话。每个短对话解决一个子问题
把长对话想象成一个桌面越来越乱的工作台。定期"清理桌面"(开新对话),只保留当前需要的材料,工作效率会高得多。
如何准备高质量材料包
四步准备流程:
- 明确AI需要知道什么 - 从任务出发,反向推导需要的信息。问自己:如果我是一个聪明但完全不了解这个项目的人,我需要知道什么才能做好这件事?
- 筛选和精简材料 - 问自己:去掉这份材料,AI输出质量会受影响吗?如果不会,就不要放进去
- 组织材料的结构 - 分区标注:任务说明、数据A、数据B、分析要求。用清晰的标题和分隔符让AI知道每部分是什么
- 标注信息的来源和可靠性 - 区分官方年报(高可靠)和网络论坛(待核实)。告诉AI哪些信息可以直接引用,哪些需要谨慎对待
上下文工程(Context Engineering)
上下文工程是指有意识地设计、组织和管理提供给AI的背景信息,以最大化AI输出质量的实践。与其花大量时间研究提示词技巧,不如花同样的时间去改善上下文质量。这就像烹饪 -- 好的食材比花哨的刀工更决定菜品质量。
以下哪种做法最能提升AI的输出质量?
'中间丢失'(Lost in the Middle)现象指的是什么?
选择你正在做的一个课程作业,列出完成这个任务需要哪些背景材料。然后思考:哪些材料是高可靠的?哪些需要标注'待核实'?
这是我的论文题目和一些资料,你帮我分析一下:(然后粘贴了3000字的混杂内容,包括题目、导师意见、几段不同来源的摘录、自己的想法、网上看到的观点......)
参考文献
朱俊仪, 朱尚明. (2024). 利用检索增强生成技术开发本地知识库应用.《通信学报》, 45(Z2):242-247. https://www.joconline.com.cn/zh/article/doi/10.11959/j.issn.1000-436x.2024227/ ↩︎ ↩︎
庞亮, 邓靖程, 顾佳, 沈华伟, 程学旗. (2024). 大语言模型时代的信息检索综述. 第23届中国计算语言学大会论文集. https://aclanthology.org/2024.ccl-2.6/ ↩︎ ↩︎