AI不是搜索引擎,也不是万能老师
图解导读:把AI从"查答案"的位置上拿下来
很多误用都来自一个起点:把AI想象成会说话的搜索引擎。可它的基本动作不是从数据库里取出一个确定答案,而是根据上下文生成一段最可能成立的文字。这个差异一旦看清,后面关于幻觉、遗漏和核验的讨论就不再吓人。
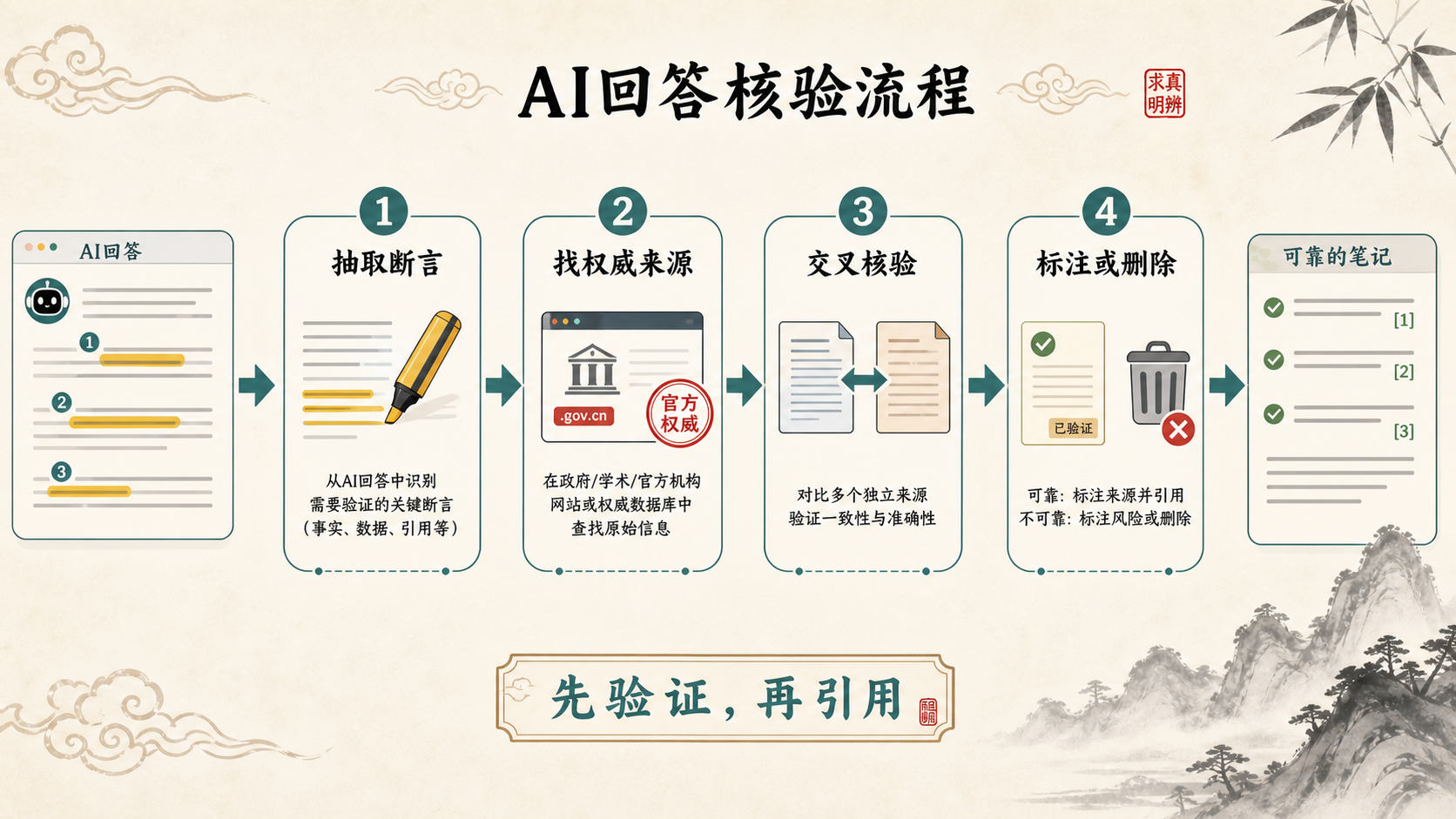
因此,使用AI时最重要的不是"它说得像不像",而是把它的回答拆成可以验证的断言。一个可靠的动作顺序是:抽取断言,找权威来源,交叉核验,最后决定标注、修改还是删除。
模型不是数据库
很多人对AI有一个直觉性的误解:它的脑子里装着一个巨大的数据库,你问它问题,它就去查一下返回答案。但AI不是数据库,它是一个经过大量文本训练出来的统计模型。
核心概念:大语言模型的本质
大语言模型(LLM)不是知识数据库,而是一个从海量文本中习得语言统计规律的概率模型。它的输出是基于上下文的概率推断结果,而非对确定事实的检索。这意味着它可能在任何时候输出一个"统计上合理但事实上错误"的回答。
它学到的是模式,不是事实。这就是为什么它可以准确地告诉你莎士比亚四大悲剧的名字,同时却会编造一个根本不存在的莎士比亚学者。
这个区别并非只是理论上的。2023年,纽约一位律师Steven Schwartz在法庭上提交了由ChatGPT生成的法律文书,其中包含六个完全虚构的案例引用。法官发现后对他进行了罚款处分[1]。这位律师并非不够聪明,他只是错误地把AI当成了一个"会查案例的数据库"。
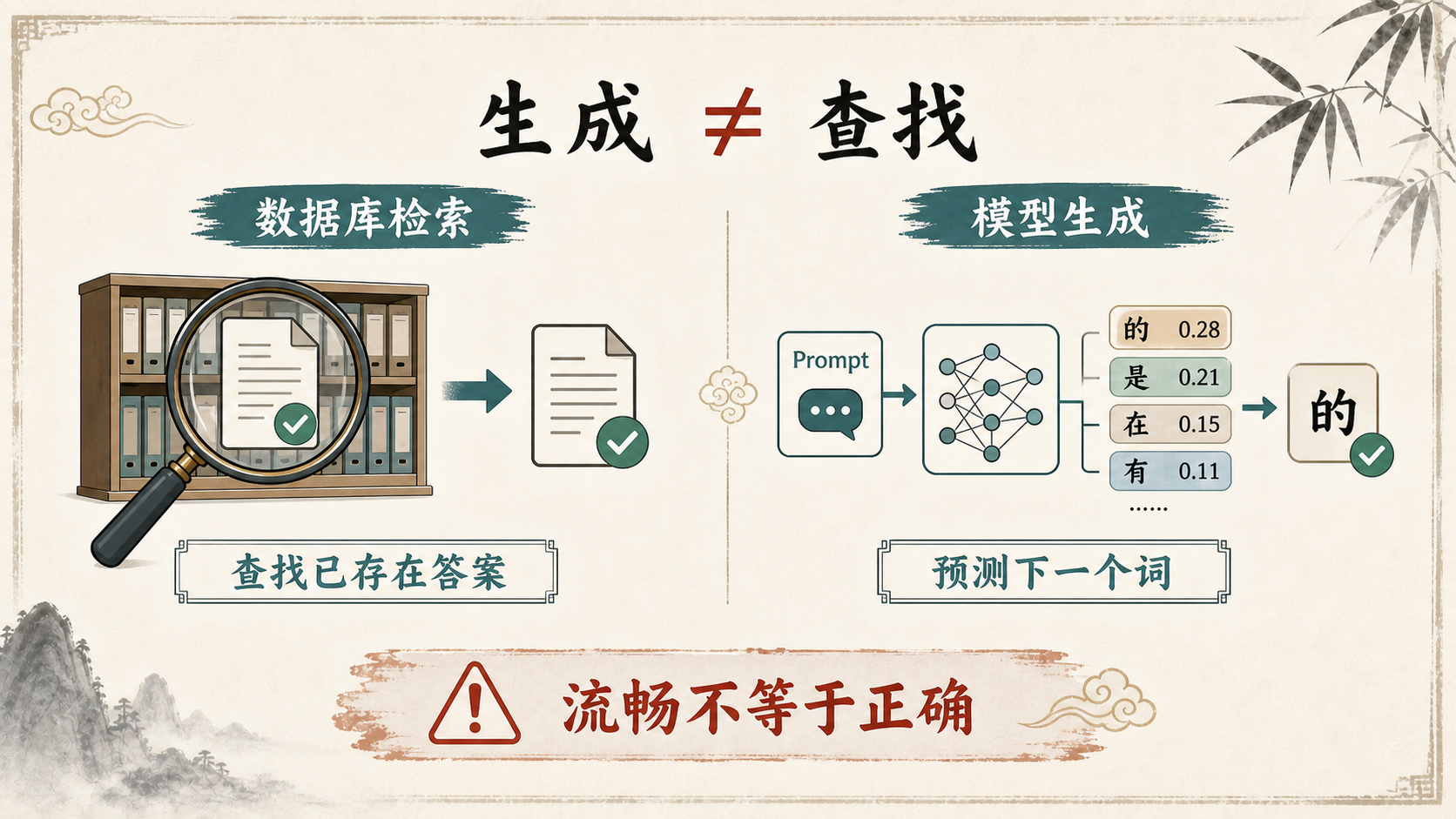
生成不是查找
AI的回答机制出乎意料地简单:它一次生成一个词,每次选择概率最高的那个。
AI的生成过程(极度简化版)
输入:"请帮我解释什么是"
第1步:在所有可能的下一个词中,"机器"的概率最高 -> 选择"机器"
第2步:序列变成"请帮我解释什么是机器","学习"的概率最高 -> 选择"学习"
第3步:继续生成......如此反复,直到整段回答生成完毕。
这个机制常被概括为"下一个词预测"(Next Token Prediction)。国内关于大语言模型幻觉的综述也指出,大模型基于大规模语料和深度学习架构生成文本,强大的生成能力并不等同于事实校验能力[2]。换句话说,模型看起来只是在"猜词",但为了猜得准,它会形成某种对语言和世界模式的内部表征。
从"猜词"到"对齐":现代模型不只是预测下一个词
上面描述的是模型的基础训练阶段。实际上,现代大语言模型在此基础上还经历了对齐训练(如RLHF,基于人类反馈的强化学习):人类评估员对模型的多个回答进行打分排序,模型据此学习什么样的回答更有帮助、更安全、更诚实。这意味着你看到的AI回答不是纯粹的"统计猜词"结果,而是经过刻意训练使其更符合人类期望的输出。但这也带来一个副作用:对齐训练让AI变得更"讨好"用户,有时会以牺牲准确性为代价来给出你想听的答案 -- 这就是上面提到的"迎合"问题的技术根源。
这个机制解释了AI的很多行为特征:
- 语法完美:因为语法正确的文本在训练数据中远多于错误的
- 有时跑题:因为每一步只看前面的词,容易顺着"统计惯性"走偏
- 编造事实:因为目标是生成"统计上最合理的序列",而不是"事实上最准确的序列"
- 风格一致:因为它学到的是"这类上下文中通常后面跟什么样的话"
理解了"生成"和"查找"的区别,你就不会再对AI的错误感到困惑 -- 它从来就不是在"查找"答案,它是在"创造"一个看起来最像答案的文本。
流畅不等于正确
人类有一个根深蒂固的认知偏差:我们倾向于相信表达流畅的信息。信息越容易被加工,我们越倾向于认为它是正确的。
在人类沟通中,这个经验法则大多数时候是有用的:一个人能把一件事说得清楚明白,通常意味着他对这件事有较深的理解。但在AI面前,这个经验法则彻底失效了。
AI最危险的特性:它犯错的时候不会降低表达质量。人类专家不确定时通常会切换到更谨慎的语气 -- "据我所知"、"不太确定但可能是"、"需要进一步核实"。AI没有这种信号,它用同样自信的语气说出正确的事实和编造的谎言。
国内研究者在《软件学报》发表的综述中把"幻觉"归纳为大语言模型可信应用中的关键风险之一:模型可能生成与输入、上下文或世界知识不一致的内容[2:1]。这提醒我们一件关键的事:不要因为AI说得好听就相信它说得对。
实用建议:读完AI的回答之后,强迫自己找出至少一个需要核实的具体断言。不是泛泛地想"这个可能有问题",而是找到一个具体的事实声明,然后去验证它。这个习惯一旦建立,你的"被骗"概率会大幅降低。
AI的四种常见失败模式
| 类型 | 表现 | 为什么难以发现 |
|---|---|---|
| 幻觉 | 生成不存在的事实、人物、文献 | 格式完美,每个零部件看起来都是真的 |
| 遗漏 | 省略关键信息而不告知 | 你很难注意到一个"不存在"的东西 |
| 迎合 | 附和用户的错误观点 | 结果是你"满意"地结束了对话 |
| 过度自信 | 不确定时仍给出确定性回答 | AI对每件事的语气都一样自信 |
这四种模式经常同时出现,并且相互强化。比如:你问了一个包含错误前提的问题("莎士比亚写《白鲸记》时在想什么?"),AI可能会迎合你的前提(不纠正莎士比亚并没有写《白鲸记》),然后编造一段看起来合理的文学分析(幻觉),同时省略任何表示不确定的措辞(过度自信),而且完全不提及遗漏了什么(遗漏)。
理解它们不是为了害怕AI,而是为了在使用时自动开启一种"校验模式" -- 就像你在马路上开车时会自然地检查后视镜,不是因为你害怕开车,而是因为你知道路上有风险。
延伸阅读
关于AI幻觉问题的系统性研究,可以参考《软件学报》发表的《大语言模型的幻觉问题研究综述》[2:2]。它对幻觉来源、评估方法和缓解方法做了系统梳理。
四要素决定AI输出质量
AI最终给你的输出质量,由四个要素共同决定:
- 模型本身的能力 - 不同模型存在差异,但差异没有大多数人以为的那么大。顶级模型和中档模型之间的差距,远小于"好的使用方法"和"差的使用方法"之间的差距
- 上下文的质量 - 你给AI的背景材料越丰富、越准确,回答质量就越高。这就是为什么第4章专门讲"上下文工程"
- 工具的接入 - 连接搜索、代码执行等工具后,AI的能力边界大幅扩展。一个配备了搜索工具的中等模型,在事实性问题上可能比没有搜索的顶级模型表现更好
- 你的知识背景与使用方式 - 你对领域的理解深度决定了你能提出多精确的要求,也决定了你能在多大程度上识别AI的错误。同一份AI输出,在专家手中和在新手手中的价值截然不同
关键认识
一个用了正确方法的人配上中等水平的模型,产出的结果往往远好于一个用了错误方法的人配上最顶级的模型。国家网信办关于《生成式人工智能服务管理暂行办法》的答记者问也强调,生成式人工智能服务需要提高生成内容的准确性和可靠性[3]。
AI的正确定位
定义:AI的正确定位
在学习和工作场景中,AI应该被视为一个高产出但需要质量控制的"内容供应商"。你是项目负责人,AI是执行者。你定义任务、提供材料、审查结果、承担责任。最终的决策权和责任永远在你手中。
三个核心动作:
- 引导:告诉AI做什么、怎么做、按什么标准做。AI没有自己的目标,你的引导就是它的方向盘
- 检查:AI的每一份输出都需要经过你的审查。审查的深度与用途的重要性成正比
- 约束:为AI的使用设定边界。哪些事情可以让AI做,哪些必须自己做,这条线由你来画
最简单的实践:AI告诉你的,再去另一个可靠来源验证一下。这个习惯是你和AI之间最重要的一道防线。
AI生成的文本读起来非常流畅且自信,这说明什么?
2023年纽约律师Steven Schwartz案例说明了什么问题?
找一个你熟悉的学科领域,向AI提一个专业问题,然后用教科书或权威文献去核实AI的回答。你发现了什么?
AI说2024年中国GDP增速是5.2%,看起来很专业,应该是对的,直接引用到论文里吧。
参考文献
新浪财经(转引环球市场播报). (2023). 美国两名律师引用ChatGPT虚构案例被罚5000美元. https://finance.sina.com.cn/stock/usstock/c/2023-06-23/doc-imyyfnhx0534059.shtml ↩︎
刘泽垣, 王鹏江, 宋晓斌, 张欣, 江奔奔. (2025). 大语言模型的幻觉问题研究综述.《软件学报》, 36(3), 1152-1185. https://www.jos.org.cn/html/2025/3/7242.htm ↩︎ ↩︎ ↩︎
国家互联网信息办公室. (2023). 国家互联网信息办公室有关负责人就《生成式人工智能服务管理暂行办法》答记者问. https://www.cac.gov.cn/2023-07/13/c_1690898326863363.htm ↩︎