AI输出七问法
图解导读:把怀疑变成一套固定动作
仅仅提醒自己"要小心AI"没有太大用,因为人在赶时间时最容易跳过检查。七问法的价值,是把模糊的谨慎变成固定动作:真实性、完整性、相关性、偏见、可执行性、来源和责任,每一项都问一遍。
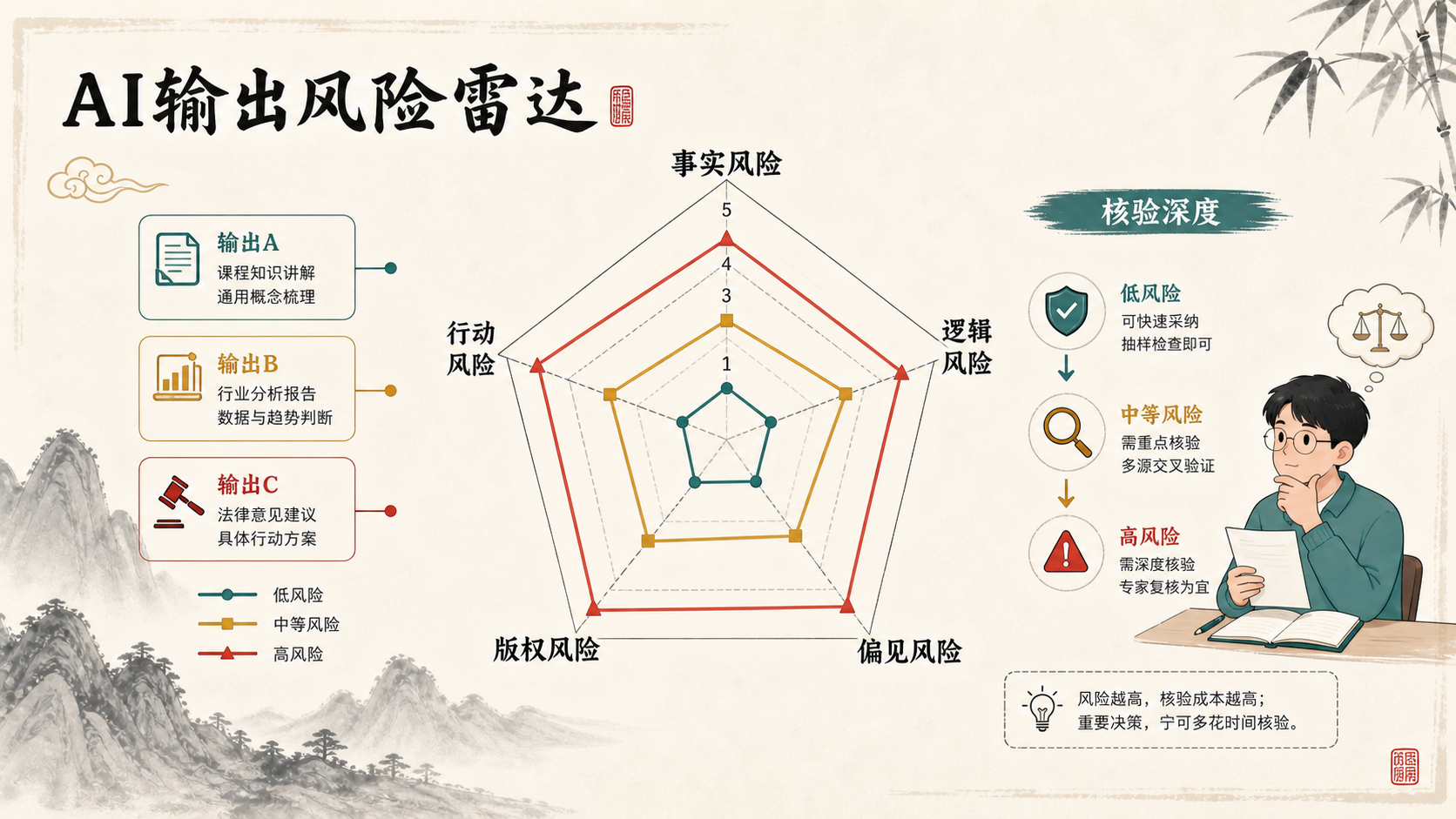
不同输出的风险不一样。闲聊建议可以轻量检查,论文引用、医疗建议、法律判断、公开发布内容则需要更深层核验。先判断风险,再决定核验深度,才不会把所有回答都当成同一种东西处理。
情境案例
一位公共管理专业的研究生让AI帮她写了一段关于"数字政务平台用户满意度"的文献综述。文字流畅、结构完整、引用了多篇论文。她差点直接用了。
但她用七问法逐一检查后发现:引用的五篇论文中有两篇根本不存在(准确性问题),综述完全没有提到负面评价的研究(完整性问题),一篇被引用的论文讨论的是电商平台而非政务平台(相关性问题)。
她花了两个小时修正这些问题,最终的综述质量远高于AI的初始输出。七问法帮她避免了一次学术事故。
为什么需要系统化的评估方法
上一章建立了"判断比生产更重要"的认知。但判断不能只靠直觉。直觉会受到AI输出的流畅度的迷惑,会因为内容"看起来对"而放松警惕。
你需要一个系统化的检查清单,在每次使用AI的重要输出之前走一遍。就像飞行员起飞前的检查清单,不是因为飞行员记不住,而是因为系统化的检查可以捕捉到直觉遗漏的问题。全国网络安全标准化技术委员会发布的《生成式人工智能服务安全基本要求》就把语料安全、模型安全、安全措施和安全评估拆成可检查的条目[1]。这给我们的启发是:对AI输出的评估不能依赖"看起来像不像对的"这种直觉判断,而应该建立可操作的检验标准。
七个问题
第一问:准确吗?
输出中的事实陈述、数据、引用是否正确?
这是最基础也最重要的一关。AI的事实性错误通常藏在两个地方:
- 具体数据:百分比、年份、金额、排名等数字
- 引用来源:论文标题、作者、发表期刊、法律条款编号
验证方法
把AI提到的关键事实拿到独立信息源去核实。不要用另一个AI来验证(它们可能犯同样的错误),而是去官方数据库、权威机构网站、学术检索平台核实。
具体操作: 抽取AI回答中的2-3个关键数据或引用,分别到中国知网(CNKI)、国家统计局官网、Google Scholar或相关行业权威网站搜索。如果查不到或与原始来源不符,该信息不可使用。
第二问:完整吗?
有没有遗漏重要的方面、视角或信息?
AI倾向于给出"平衡"的回答,但平衡不等于完整。它可能系统性地忽略了某些视角:
- 少数派观点或争议性立场
- 最新的进展(训练数据截止后的信息)
- 特定地区或文化背景下的差异(很多AI的训练数据以英语世界为主,可能忽略中国国情)
- 反面证据和失败案例
具体操作: 读完AI输出后问自己:"这个话题还有哪些重要视角没有被讨论?"然后主动追问 AI:"你的回答有没有遗漏重要的反面证据或少数派观点?"
第三问:相关吗?
输出是否真的在回答我问的问题?
AI经常"答非所问"但你不容易察觉,因为它的回答看起来和你的问题是相关的。这是一种更隐蔽的失败 -- 它没有说错话,但说了一堆不需要的"正确的话"。
区分两种情况:
- 表面相关:讨论了同一个话题,但没有回答你的具体问题
- 实质相关:直接针对你的具体问题给出了有价值的信息
第四问:清晰吗?
表达是否清楚、结构是否合理、重点是否突出?
好的输出应该让读者轻松抓住核心信息。检查:
- 有没有不必要的重复和冗余
- 关键信息是否被埋在大段文字中
- 逻辑结构是否清晰(先说什么、后说什么)
第五问:一致吗?
输出内部是否自相矛盾?与已知事实是否冲突?
AI在长文本中容易出现前后矛盾:前面说"A因素是主要原因",后面又说"A因素的影响有限"。这种不一致不是因为AI在故意骗你,而是因为它在不同段落中被不同的上下文"牵引"到了不同方向。你需要主动去捕捉这种矛盾。
第六问:可用吗?
这个输出能直接用在我的实际场景中吗?
可用性检查的核心是场景适配:
- 语言风格是否适合你的受众(学术论文 vs. 商业报告 vs. 日常交流)
- 格式是否符合你的要求
- 深度是否匹配你的需求
- 是否需要额外的本土化处理(例如法律分析中的中外法律差异)
第七问:负责吗?
使用这个输出会不会带来伦理、法律或信誉风险?
- 是否涉及他人隐私或敏感信息
- 是否包含偏见或歧视性内容
- 引用的来源是否真实存在
- 直接使用是否构成学术不端
科技部监督司发布的《负责任研究行为规范指引(2023)》明确提出,使用生成式人工智能生成的内容,特别是涉及事实和观点等关键内容的,应明确标注并说明其生成过程,确保真实准确并尊重他人知识产权[2]。
不同场景下的评估侧重
不是每次都需要对七个问题同等投入。根据使用场景调整侧重:
| 场景 | 重点关注 | 可以相对放松 |
|---|---|---|
| 学术论文 | 准确、完整、负责 | 清晰(可以自己润色) |
| 日常学习笔记 | 准确、清晰 | 完整、格式 |
| 商业报告 | 相关、可用、一致 | 完整性(聚焦即可) |
| 代码生成 | 准确、可用 | 清晰(代码能跑就行) |
| 创意写作 | 相关、清晰 | 准确性(允许虚构) |
| 政策分析 | 准确、完整、一致、负责 | 格式可调整 |
把七问法变成习惯
七问法不需要你每次都拿着清单一项项打勾。它的目标是内化为一种思维习惯:
快速版:三秒扫描
拿到AI输出后,快速问自己三个问题:
- 这里面有没有可能是错的?(准确)
- 这真的是在回答我的问题吗?(相关)
- 我敢直接用这个吗?(负责)
如果三个答案都是"是",可以使用。如果任何一个是"不确定",切换到完整的七问检查。
本章核心回顾
- 七问法是一个系统化的AI输出质量评估框架
- 七个维度:准确、完整、相关、清晰、一致、可用、负责
- 不同场景侧重不同,学术场景重准确和负责,商业场景重相关和可用
- 目标是内化为习惯,从刻意检查变为自然反应
- 快速版三秒扫描:准确?相关?负责?
AI帮我写了一段文献综述,读起来很顺畅、引用也很规范,看上去没问题,直接插入论文了。
用AI帮你写了一段学术论文的文献综述,你应该优先检查哪个维度?
七问法中'相关性'检查要区分的两种情况是什么?
打开你最近一次使用AI生成的内容,用'快速版三秒扫描'检验一遍:准确吗?相关吗?负责吗?你发现了什么问题?
设计一个适合你专业的'七问法变体'。比如,如果你是法学生,第一问可能不只是'准确吗',而是'法条引用和判例引用是否可核实'。为你的专业定制一个版本。
参考文献
全国网络安全标准化技术委员会. (2024).《生成式人工智能服务安全基本要求》(TC260-003). https://www.tc260.org.cn/upload/2024-03-01/1709282398070082466.pdf ↩︎
科技部监督司. (2023).《负责任研究行为规范指引(2023)》. https://www.most.gov.cn/kjbgz/202312/t20231221_189240.html ↩︎