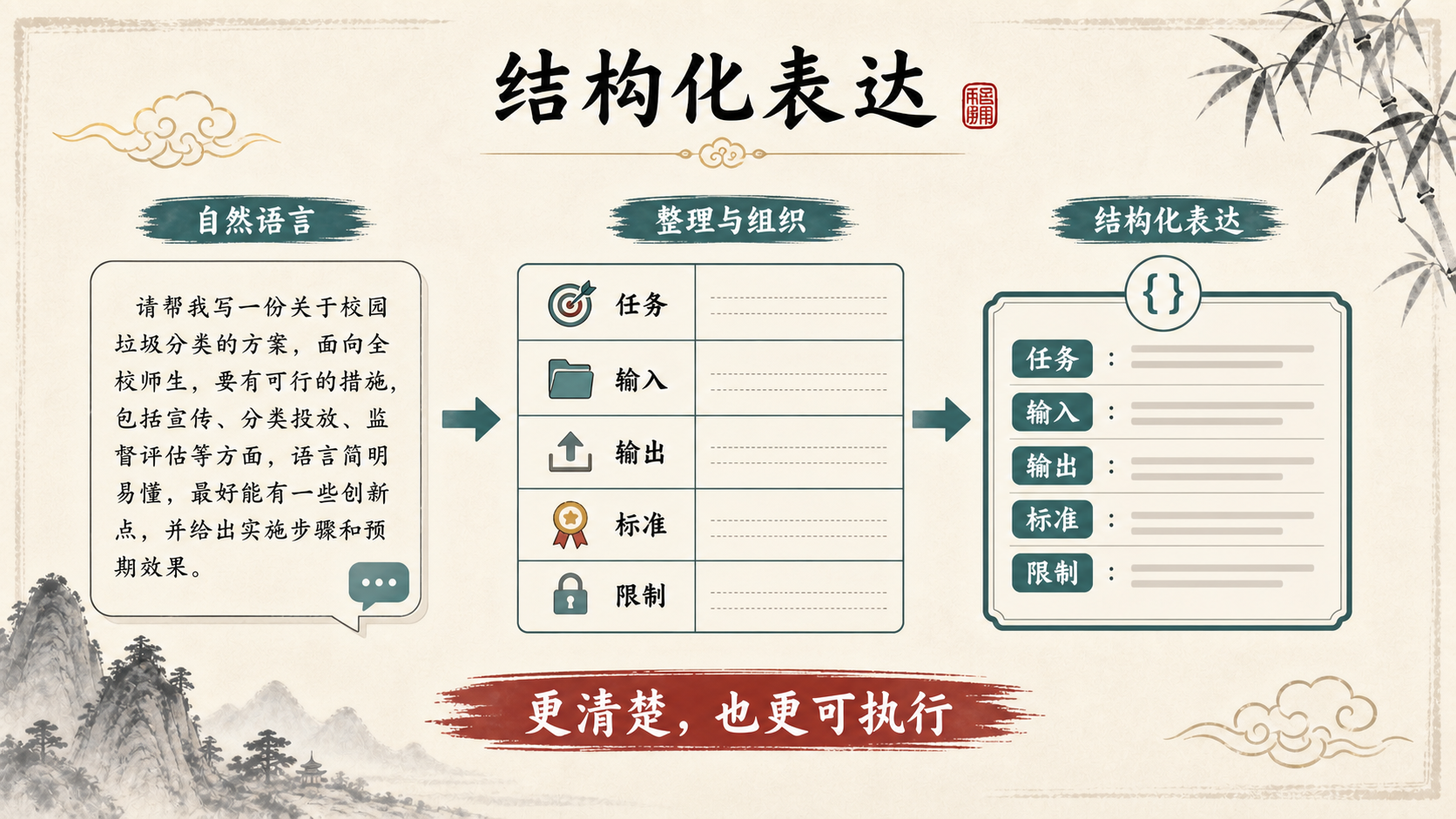
结构化表达
图解导读:把话说清,也把结构交代清
自然语言灵活,但容易含混;结构化表达不够优雅,却更容易检查、复用和交给工具处理。AI协作中,很多失败不是因为模型不聪明,而是因为输入和输出没有稳定结构。
当AI回答必须依赖材料时,结构化也能帮助你把"来源"放回答案里。知识库、检索、生成和核验之间的关系,不必一开始就理解得很技术;先记住一个原则:答案必须能回到材料来源。
什么是结构化表达
人类用自然语言沟通,灵活但模糊。机器用结构化数据沟通,精确但死板。AI处在两者之间:它理解自然语言,但在需要与工具协作时,必须输出结构化数据。
这种"灵活"与"精确"之间的张力,是你在AI时代需要理解的一个核心矛盾。你不需要成为程序员,但你需要理解为什么有些信息需要用结构化的方式表达。
一个例子
自然语言:"帮我查一下明天武汉的天气,要温度和湿度"
结构化表达:
{
"city": "武汉",
"date": "2026-03-15",
"metrics": ["temperature", "humidity"]
}两种表达传递的信息相同,但结构化版本没有歧义,机器可以直接处理。自然语言版本中的"明天"需要被转化为具体日期,"温度和湿度"需要被映射为标准化的字段名。这种转化过程就可能引入错误。
JSON:最通用的结构化格式
JSON(JavaScript Object Notation)是互联网上最广泛使用的数据交换格式。无论你打开哪个网站、使用哪个App,它们在后台交换数据时大概率使用的就是JSON。
核心语法:
- 用
{}表示对象(键值对的集合) - 用
[]表示数组(有序列表) - 键名用双引号包裹
- 值可以是字符串、数字、布尔值、数组或嵌套对象
{
"name": "张三",
"age": 21,
"major": "新闻传播学",
"skills": ["写作", "数据分析", "AI协作"],
"graduated": false
}你不需要学会"写"JSON,但你需要能"读"JSON -- 因为当AI调用工具、处理数据时,你会频繁看到这种格式。能读懂它,你就能理解AI在做什么。
YAML:更适合人类阅读的格式
YAML用缩进代替了JSON的大括号和引号,更易读写:
name: 张三
age: 21
major: 新闻传播学
skills:
- 写作
- 数据分析
- AI协作
graduated: falseJSON vs YAML
- JSON:机器处理更友好,几乎所有编程语言都原生支持
- YAML:人类阅读更友好,常用于配置文件(如GitHub Actions、Docker等)
- 两者可以相互转换,表达能力等价
- 如果你不确定用哪个,选JSON -- 它的通用性更强
Schema:结构的合约
Schema定义了"数据应该长什么样"。它是生产者和消费者之间的合约。
比如一个"学生信息"的Schema规定:name必须是字符串,age必须是正整数,skills必须是字符串数组。任何不符合Schema的数据会被拒绝。
Schema在AI协作中的作用:当AI调用工具时,Schema告诉AI每个工具需要什么参数、什么格式。Schema越清晰,AI生成正确参数的概率越高。
JSON.org 对JSON的介绍强调,JSON是一种轻量级数据交换格式,便于人阅读和编写,也便于机器解析和生成[1]。当AI需要操作外部世界时 -- 查天气、发邮件、查数据库 -- 它必须把自然语言意图转化为结构化的指令,Schema就是这种转化的"翻译词典"。
结构化输出的价值
| 维度 | 自然语言输出 | 结构化输出 |
|---|---|---|
| 可检查 | 需要人逐字阅读 | 可以用程序自动校验 |
| 可复用 | 每次需要重新解析 | 可直接被其他系统使用 |
| 可组合 | 难以与其他数据合并 | 可以自动合并、筛选、排序 |
| 一致性 | 格式随AI心情变化 | 每次输出格式统一 |
什么时候需要结构化输出
- 你的AI输出需要被其他程序或工具处理时
- 你需要对大量AI输出进行批量检查时
- 你需要把AI输出存入数据库时
- 你需要AI的输出格式每次都一致时
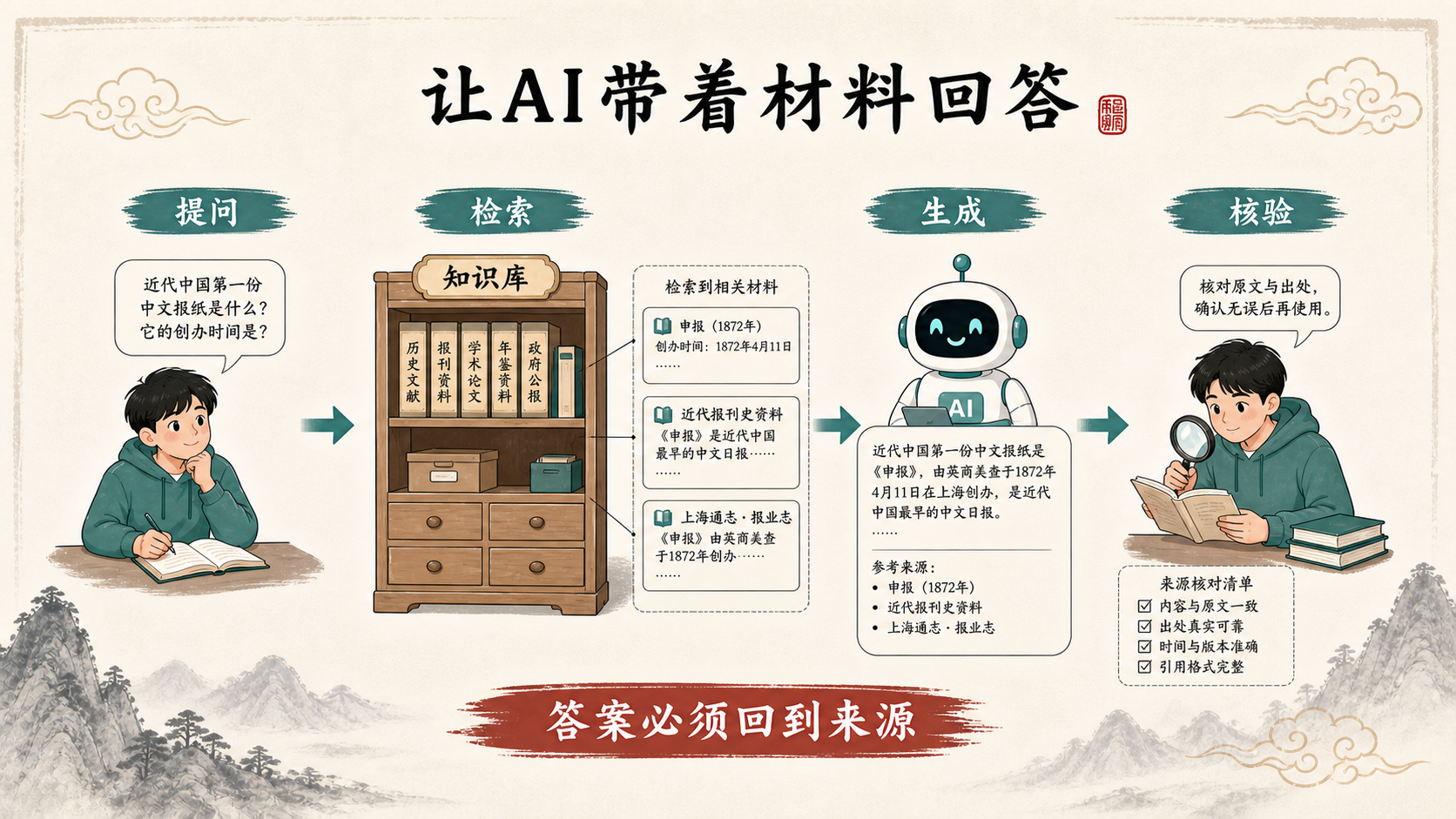
RAG:让AI获取外部知识
RAG(Retrieval-Augmented Generation,检索增强生成)是一种让AI在回答问题时,先从外部知识库中检索相关信息,再基于检索到的信息生成回答的技术。
为什么需要RAG? AI的训练数据有时效限制,且不包含你的私有文档。RAG让AI可以"查阅"你提供的资料后再回答,大幅提升回答的准确性和针对性。
RAG的基本流程:
- 你的文档被切分成小段,存储在向量数据库中
- 用户提问时,系统先从数据库中检索最相关的文档片段
- 相关片段和用户问题一起发送给AI
- AI基于这些真实资料生成回答
国内很多AI产品已经内置了RAG能力。比如Kimi的"文件对话"功能、通义千问的"文档分析"功能,本质上都是在使用RAG技术 -- 它们先从你上传的文件中检索相关内容,再基于这些内容回答你的问题。《通信学报》关于本地知识库应用的文章指出,RAG通过引入外部文档,让大模型能够访问外部知识库,从而生成更真实可靠的回答[2]。
RAG的局限性
RAG不是万能的。它的效果取决于:(1) 切分质量 -- 文档被切成多大的小段影响检索精度,切得太细会丢失上下文,切得太粗会淡化关键信息;(2) 检索相关性 -- 向量相似度不等于语义相关性,系统可能找到词汇相似但与问题无关的段落;(3) 材料质量 -- 如果原始文档本身就包含错误,RAG会“基于错误生成更多错误”。因此,即使AI"查阅了你的文档",其回答仍然需要你的判断。
本章核心回顾
- 结构化表达让信息从模糊变为精确,从一次性变为可复用
- JSON是最通用的结构化格式,YAML更适合人类阅读
- Schema是数据结构的合约,确保AI和工具之间的沟通准确
- RAG让AI可以基于你的私有文档回答问题,是解决幻觉问题的有效手段
帮我分析这五篇论文的研究方法和主要发现。
Markdown、JSON、YAML这三种格式的共同特点是什么?
RAG技术解决的核心问题是什么?
把你手边的一份课程笔记改写成Markdown格式:加上标题层级、列表、和一个表格。你觉得结构化之后,信息更清晰了吗?
参考文献
JSON.org. Introducing JSON. https://www.json.org/json-en.html ↩︎
朱俊仪, 朱尚明. (2024). 利用检索增强生成技术开发本地知识库应用.《通信学报》, 45(Z2), 242-247. https://www.joconline.com.cn/zh/article/doi/10.11959/j.issn.1000-436x.2024227/ ↩︎